13 minutes
Reddit and language data part 1 - Analysing text
Introduction
I’m barely on Reddit these days.
However, when I was on Reddit, I found it interesting how different Reddit communities (‘subreddits’) seemed to have distinct flavours in the way users socially contribute to their forum.
Since Reddit is a host for a diverse group of communities banded around interests, it would follow that the type of language used in each subreddit would have its own special signature of popular word choices, sentiments, and social dynamics.
I knew there would be fascinating ways to analyse and compare the language data of different subreddits. So, I decided to start a project where I’d scrape data from different subreddits and do some linguistic analysis on the comments. I was most interested in comparing the differences between selected subreddits.
For this post, I will make comparisons of word data between two subreddits:
- r/productivity, a subreddit that “shares tips and tricks for being more productive”, and
- r/antiwork, a subreddit where users are “curious about ending work” and “want to get the most out of a work-free life”
I chose these two subreddits for this post since they both relate to the topic of work, but they approach the topic from very different perspectives. They are also both significant communities on Reddit, with r/productivity having almost 900,000 members at the time of writing and r/antiwork having 1.5 million “idlers”. So, I made a bet that contrasting the language used in these two communities could lead to some interesting insights.
To start this project, I kept it very simple. My first task focused on word frequency analysis, that is, finding insights from how often certain words appear in a sample of data (e.g. the word “cup” appears 5 times in a sample paragraph).
In this post, I will explore how I obtained the top 20 nouns and adjectives in r/productivity and r/antiwork. Towards the end, I do a little bit of armchair analysis into why these top nouns and adjectives might occur in the sampled data.
Step 1: Setting up the required Python libraries
For this step, I will presume that you’ve already got a version of Python 3 and whatever IDE you use on your computer. You’ll also need to install nltk and pandas Python libraries as well as the praw API, if you haven’t already - you can find links to each respectively here, here and here.
At the top of my script, I imported the nltk, praw and pandas libraries since I’d need these later in the script. For the nltk library, I made sure to specifically import the word_tokenize and pos_tag modules, since we’ll be needing this to analyse the words in the language data.
import nltk
from nltk import word_tokenize
import nltk.data
from nltk.probability import FreqDist
from nltk.tag import pos_tag
import praw
import pandas as pd
Step 2: Accessing the subreddits
The PRAW API was the element that connected my Python script to the actual Reddit data itself. This is the part that ‘scrapes’ the real data. For this step, I had to first register an application on Reddit. Once this was set up, I used the following code to authenticate my script to access Reddit (the ‘XXX’ details in this code will depend on the user details of your reddit application):
# access reddit
reddit = praw.Reddit(client_id='XXX',
client_secret='XXX', \
user_agent='XXX')
Next, I had to assign variables that accessed specific subreddits of r/antiwork and r/productivity. I used the reddit.subreddit() function, putting the subreddits (‘antiwork’ and ‘productivity’) into each parameter:
# assign initalising variables to the four subreddits - connect to them via reddit API
antiwork = reddit.subreddit('antiwork')
productivity = reddit.subreddit('productivity')
This connected my script to the r/antiwork and r/productivity subreddits.
Now time for the real fun!
Step 3: Collecting the data
Now that I had access to the subreddits, a question popped into my head. What type of data did I want to scrape from these communities?
Submissions to Reddit come in various data formats such as text, images, links, and videos. When I looked at the subreddits with my naked (human) eye, I noticed that a lot of submissions (the contributions created by ‘original poster’ users) were in the image data format. This kind of format was useless for what I was trying to do with my project since I needed actual text to make sense of the data linguistically. As a result, I narrowed the format of my data collection to subreddit comments, since they contained the most raw text that I needed for linguistic analysis.
I assigned variables to the PRAW comments() function that scraped 300 comments from r/antiwork and r/productivity respectively:
# sample 300 comments from each subreddit
antiwork = antiwork.comments(limit=300)
productivity = productivity.comments(limit=300)
This action doesn’t access the actual text from the comments, only the data objects. So, to get the actual text from the comments, I wrote a general function that can take raw text (comment.body) from each comment for any selected subreddit:
# return raw text from comments
def return_comments(community):
return [comment.body for comment in community if discord_string not in comment.body]
The result of this was a list of strings that contained the raw text of 300 comments from the selected subreddit.
Then, I applied this function to the 300 sample comments from the two communities:
# create corpora training data for each subreddit based on top-level comments
antiwork_corpus = return_comments(antiwork)
productivity_corpus = return_comments(productivity)
When I printed one of these variables, the result was a list of 300 raw comment strings scraped from the selected subreddit community (the result below is an example from r/antiwork):

At this point, the raw textual comment data has been pulled from the selected subreddits and put into a list. Each item in this list is a long multi-word string. However, to make sense of data linguistically, we need more than just raw strings of data. We need to tokenize the data, or in other words, split the raw strings up into smaller parts such as words or punctuation. In this way, we can grapple with the linguistically meaningful parts of our data and do some analysis!
Step 4: Words - tokenizing and analysing parts-of-speech
Since I was looking for the top 20 nouns and adjectives in the subreddit communities, it made sense to aim for actual words in my tokenize data (as opposed to sentences or punctuation).
I started off writing a function that used the tokenize() module from the nltk library. Since I was also looking at all the words in the corpus (not of any specific user comments), I used the “”.join Python command to link all the comments of the corpus words together in one big list (as opposed to a list of lists).
I applied this function to the antiwork_corpus and productivity_corpus variables:
# tokenize corpora
def tokenize(community):
return word_tokenize("".join(community))
tokenized_antiwork = tokenize(antiwork_corpus)
tokenized_productivity = tokenize(productivity_corpus)
I applied the nltk.pos_tag() function to the tokenized data for both subreddits. This would apply a part-of-speech tag (in other words, their linguistic category) to each word in the tokenized list.
# tag corpus words for part of speech
tagged_antiwork = pos_tag(tokenized_antiwork)
tagged_productivity = pos_tag(tokenized_productivity)
The result of this function was a list of tuples where each tuple had the word and their corresponding part-of-speech tag. You can see some examples in the printed list below:

So, now I was getting somewhere - I had scraped comments, tokenized the data, and assigned part-of-speech tags to the tokenized data.
Step 5: Frequency distributions of nouns and adjectives
For this part of the project, I was interested specifically in nouns and adjectives since they would provide more insight into the tone of the subreddits (as opposed to grammatical, functional words like “the” or “an” that don’t provide much meaning or sentiment in themselves).
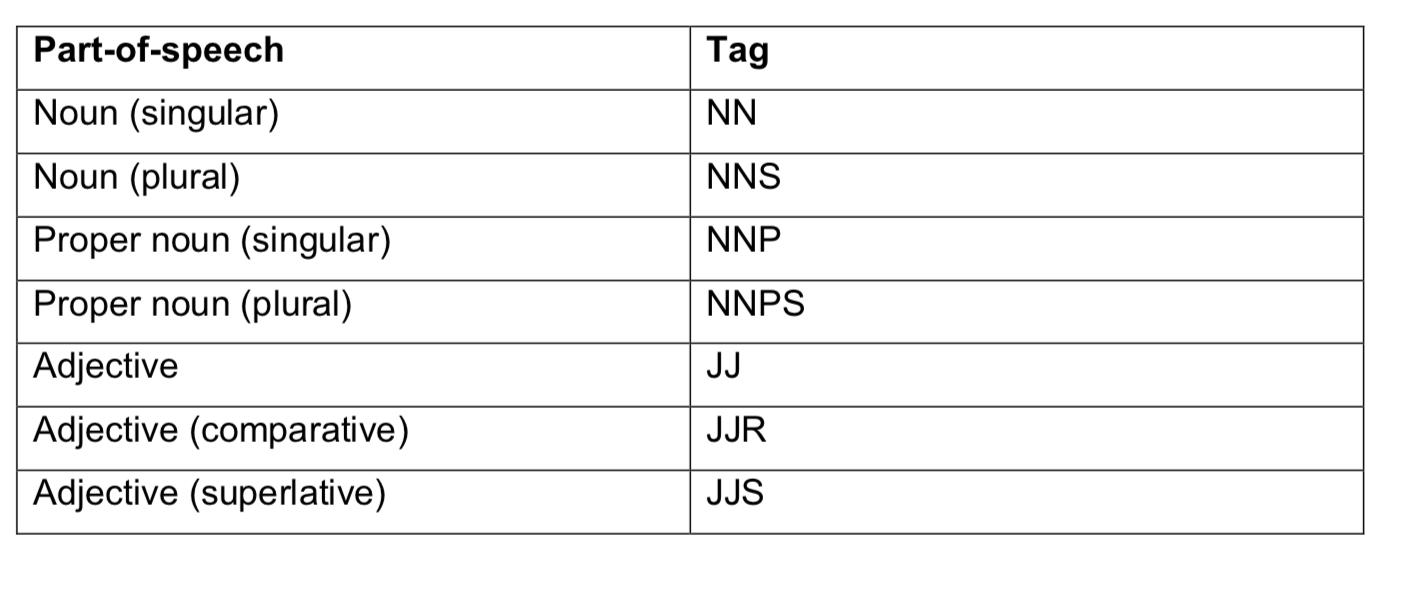
The nltk tag set divides up the general categories of nouns and adjectives into many more sub-categories that reflect more detailed elements such as noun singularity or plurality or whether an adjective is comparative or superlative. You can see the various tags in the table below:
For what I was looking for (the top 20 nouns and adjectives in a subreddit), I made a pragmatic decision to lump these sub-categories together into the two general categories of nouns and adjectives. The conversions can be seen in the added third column in the table below.
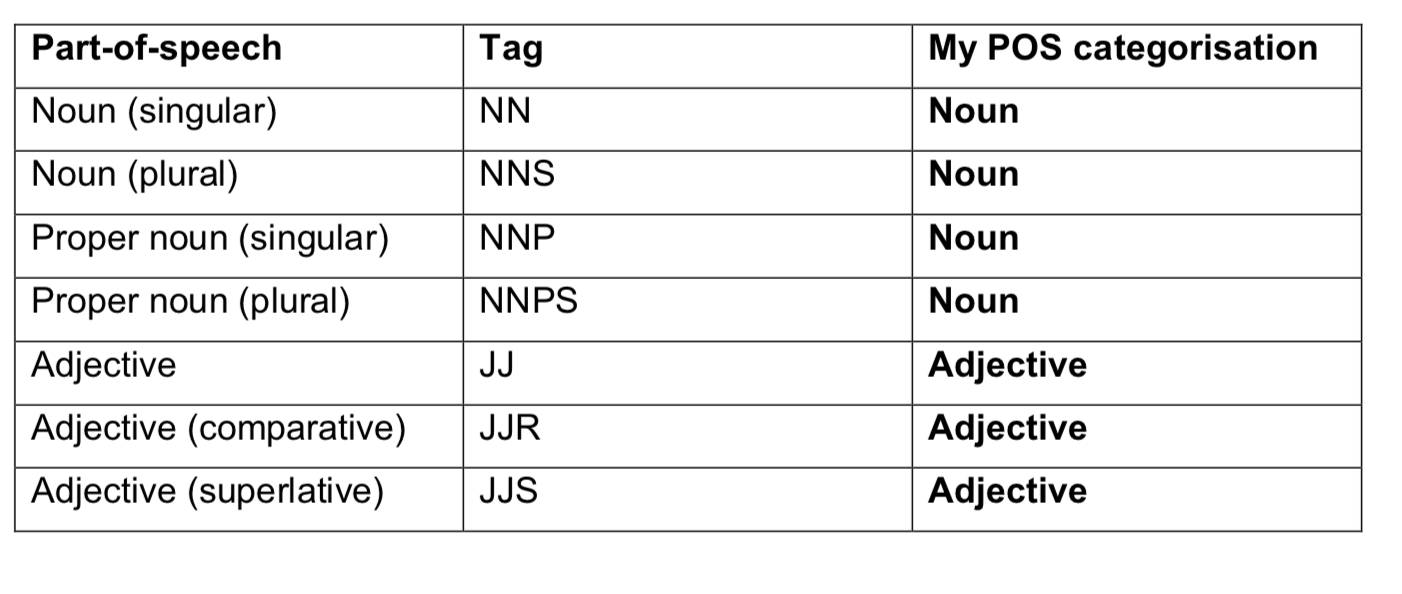
In my code, to re-assign the part-of-speech tags to my more generalised categories, I created lists that lumped the more specific tags together (e.g. ‘NN’ or noun singular or ‘NNPS’ or proper noun plural).
# PARTS OF SPEECH
# noun singular, noun plural, proper noun singular, proper noun plural
nouns = ['NN', 'NNS', 'NNP', 'NNPS']
# adj, adj comparative, adj superlative
adjs = ["JJ", "JJR", "JJS"]
In doing this, I would still be using the sub-categories of the nltk library to pick up nouns and adjectives in the comment data, but I would be putting the words into more general part-of-speech lists.
Next, I had to generate a frequency distribution of the nouns or adjectives in the word data for a given subreddit. The frequency distribution would return information on how many times a particular noun or adjective appeared in the data and list this information alongside the counts of the other nouns or adjectives in the sample
I made a function (freq_words) that used a list comprehension to pull out word forms according to their corresponding part-of-speech tags.
# retrieve freqs for nouns & adjectives
def freq_words(community, pos_tag):
return nltk.FreqDist([x[0] for x in community if x[1] in pos_tag and len(x[0]) > 2 and x[0] != "https"])
In this function, I made sure that the words pulled would be three or more characters long, to filter out punctuation and grammatical words like ‘the’ or ‘an’. I also filtered out the string “https” since this wasn’t a real word but was often found where a user had posted a link to the community. Finally, I selected the surface form of the word to put into my frequency distribution instead of selecting both the surface form and the nltk tag (e.g. “JJ”). I thought our data plots would be neater without the sub-category tags.
I applied this function to the noun and adjective word data in r/productivity and r/antiwork:
# antiwork frequency distribution (nouns/verbs/adjectives)
antiwork_nouns = freq_words(tagged_antiwork, nouns)
antiwork_adjs = freq_words(tagged_antiwork, adjs)
# productivity frequency distribution (nouns/verbs/adjectives)productivity_nouns = freq_words(tagged_productivity, nouns)
productivity_adjs = freq_words(tagged_productivity, adjs)
So, now I had frequency distributions for nouns and adjectives for both the r/antiwork and r/productivity comment data. Now it was time for me to visualise the data and find the most common words in the comments.
Step 6: Plotting the top 20 nouns and adjectives for each subreddit
Now that I had frequency distributions for the nouns and adjectives in both r/antiwork and r/productivity, it was time to see what the top 20 words were in these subreddits.
I used the pandas plot function to plot the top 20 nouns and adjectives for each subreddit:
# TOP 20 NOUNS
productivity_nouns.plot(20, cumulative=False, title="Top 20 r/productivity nouns")
antiwork_nouns.plot(20, cumulative=False, title="Top 20 r/antiwork nouns")
# TOP 20 ADJECTIVES
productivity_adjs.plot(20, cumulative=False, title="Top 20 r/productivity adjectives")
antiwork_adjs.plot(20, cumulative=False, title="Top 20 r/antiwork adjectives")
The result of these were a set of graphs that visually plotted the counts of the top 20 words in the subreddit for each part-of-speech as a decreasing frequency distribution.
Let’s have a look at them below!
Insight 1: Nouns
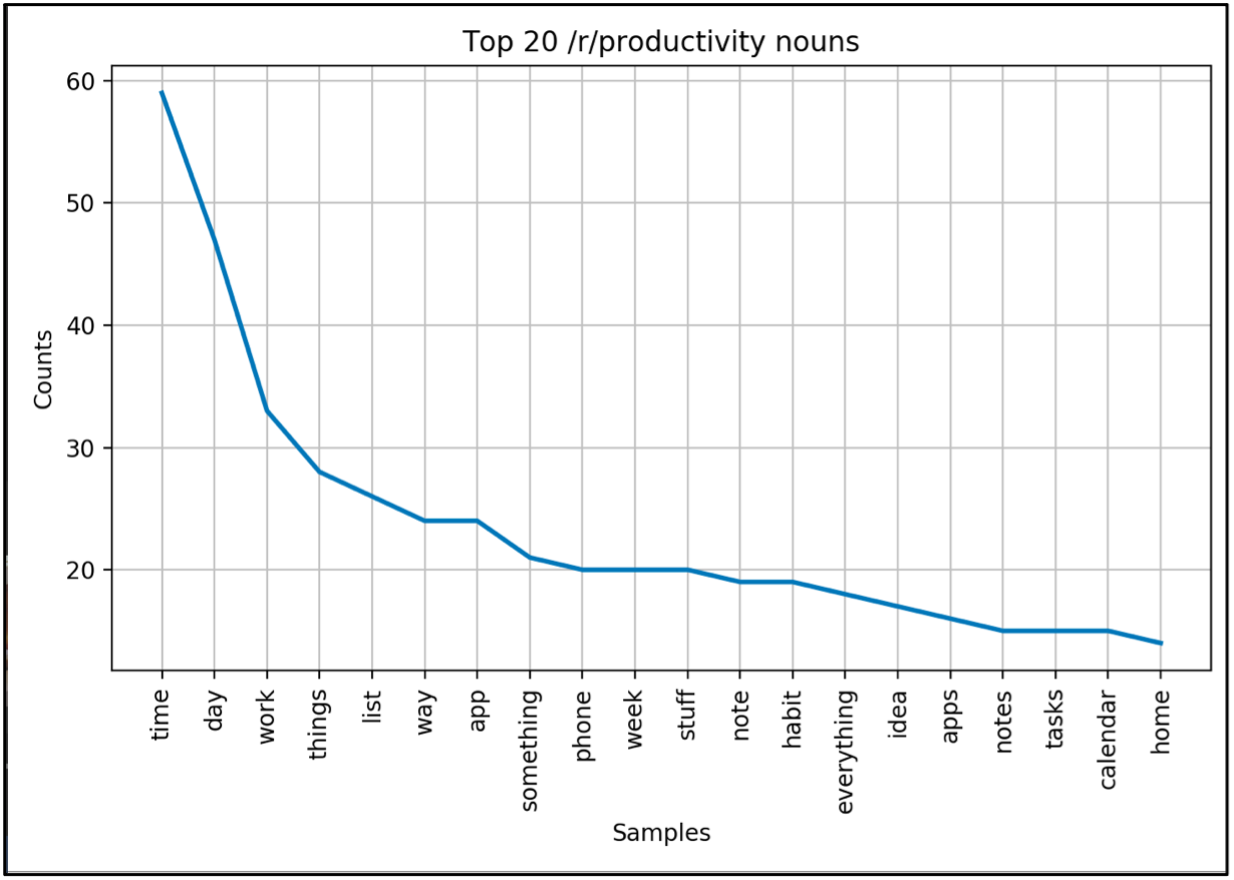
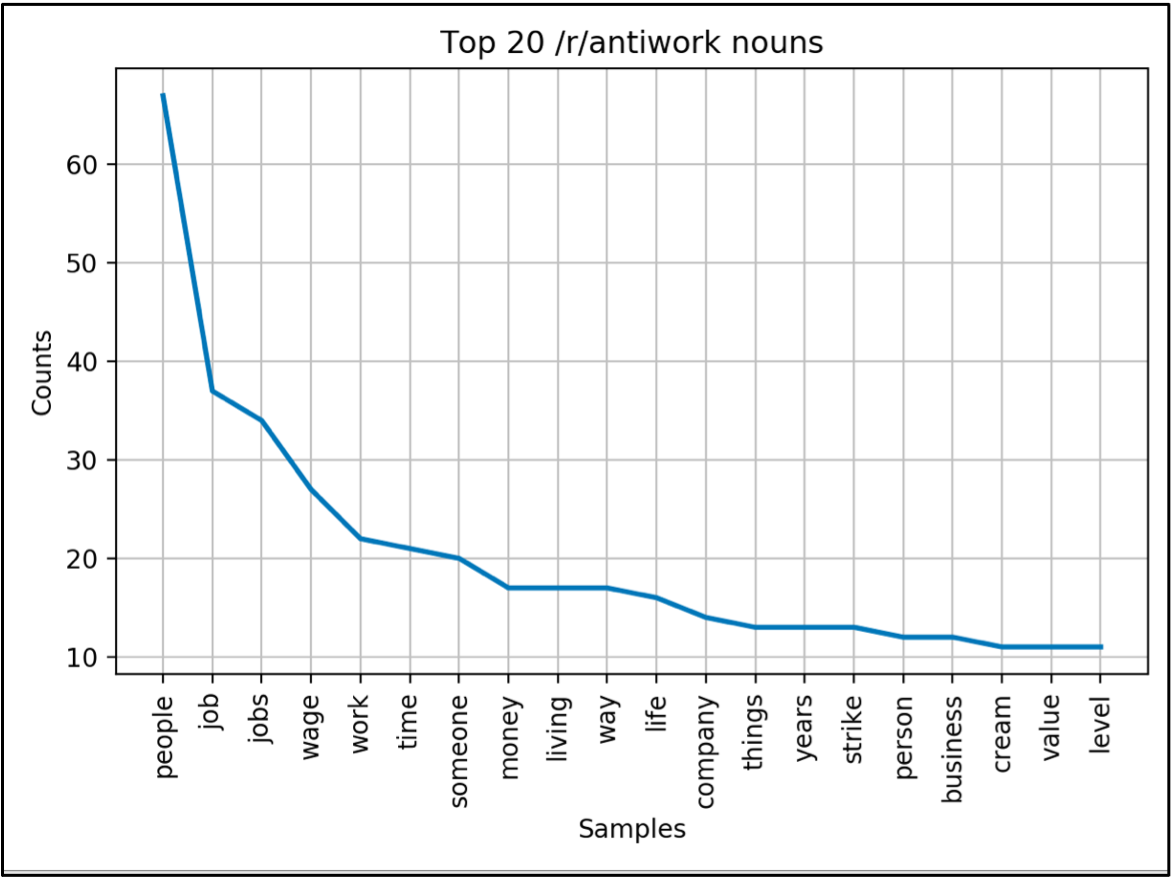
The top 20 nouns in r/productivity contained topics related to time (‘time’, ‘day’, ‘week’), executive functioning (‘list’, ‘note’/’notes’, ‘habit’, ‘tasks’, ‘calendar’) and objects (‘things’, ‘app’/’apps’, ‘phone’, ‘stuff’). The top 20 nouns in r/antiwork contained more topics related to people (‘people/person’, ‘someone’) and business and societal systems (‘job’/’jobs’, ‘wage’, ‘work’, ‘money’, ‘company’, ‘business’).
Some of the top nouns in this data were related to the concept of time. The top noun lists of r/antiwork and r/productivity both had words related to time. However, the temporal words in r/productivity seemed to relate to an interest in the short-term (‘day’, ‘week’) but r/antiwork seemed to relate to an interest in the long-term (‘years’, ‘time’, ‘life’). You could say that r/productivity and r/antiwork are both interested in time, but r/productivity users focus on the week-by-week perspective while r/antiwork users focus on time on a macro scale.
Another comparison I could make is the use of nouns related to objects as opposed to nouns related to societal systems. The r/productivity data contained more nouns related to objects (e.g. ‘list’, ‘phone’, ‘stuff’, ‘notes’), while the r/antiwork data contained more nouns related to people or societal constructs (‘people’, ‘wage’, ‘living’). This could reflect the tendency of r/productivity users to seek practical tools to complete their work, r/antiwork users to be more interested in critically evaluating the systemic issues that exist in their work in the first place.
Overall, looking at the most common nouns that occur in these two contrasting subreddits can give us some indication of the types of things people tend to talk about in these communities.
Insight 2: Adjectives
Looking at adjectives in language data can give us an indication of the emotions of users in a subreddit. Some adjectives connotate positive emotions like joy, excitement, and motivation, while other adjectives can denote negative emotions like anger, resentment, and apathy.
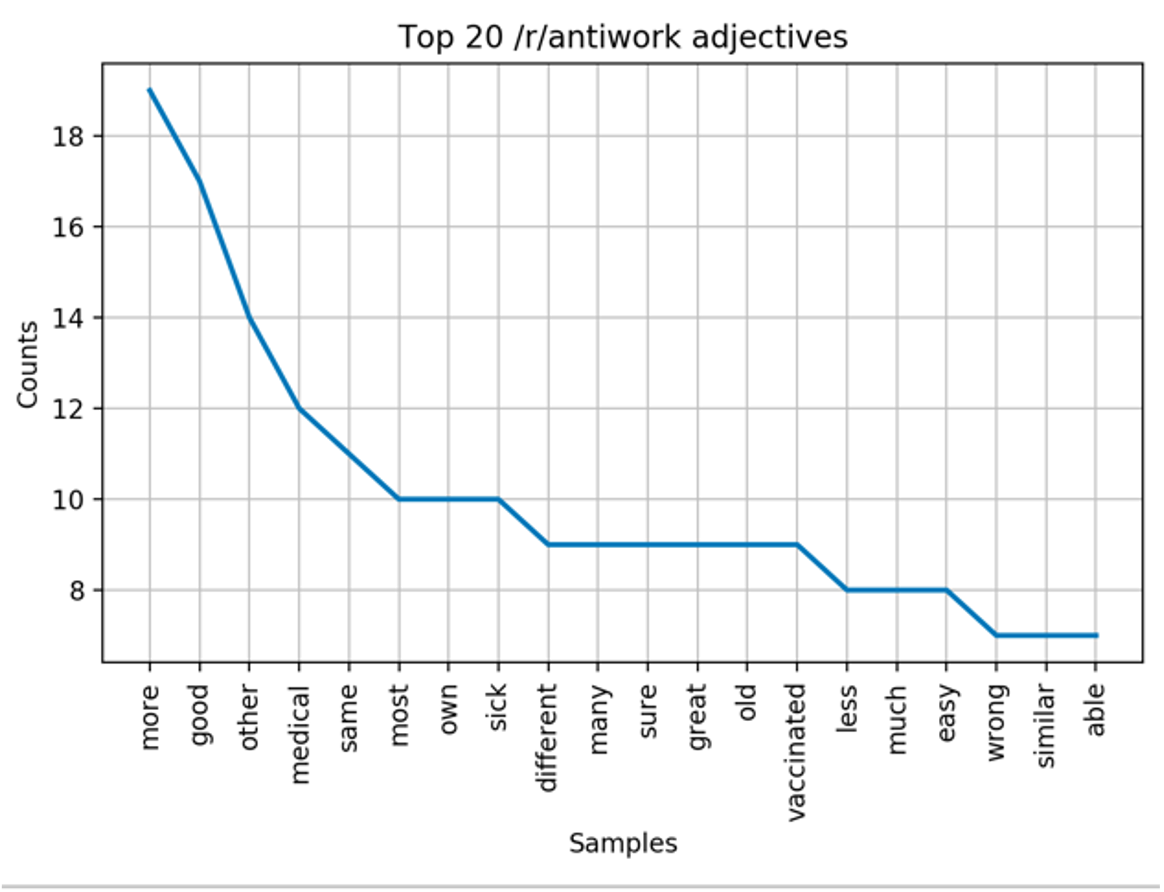
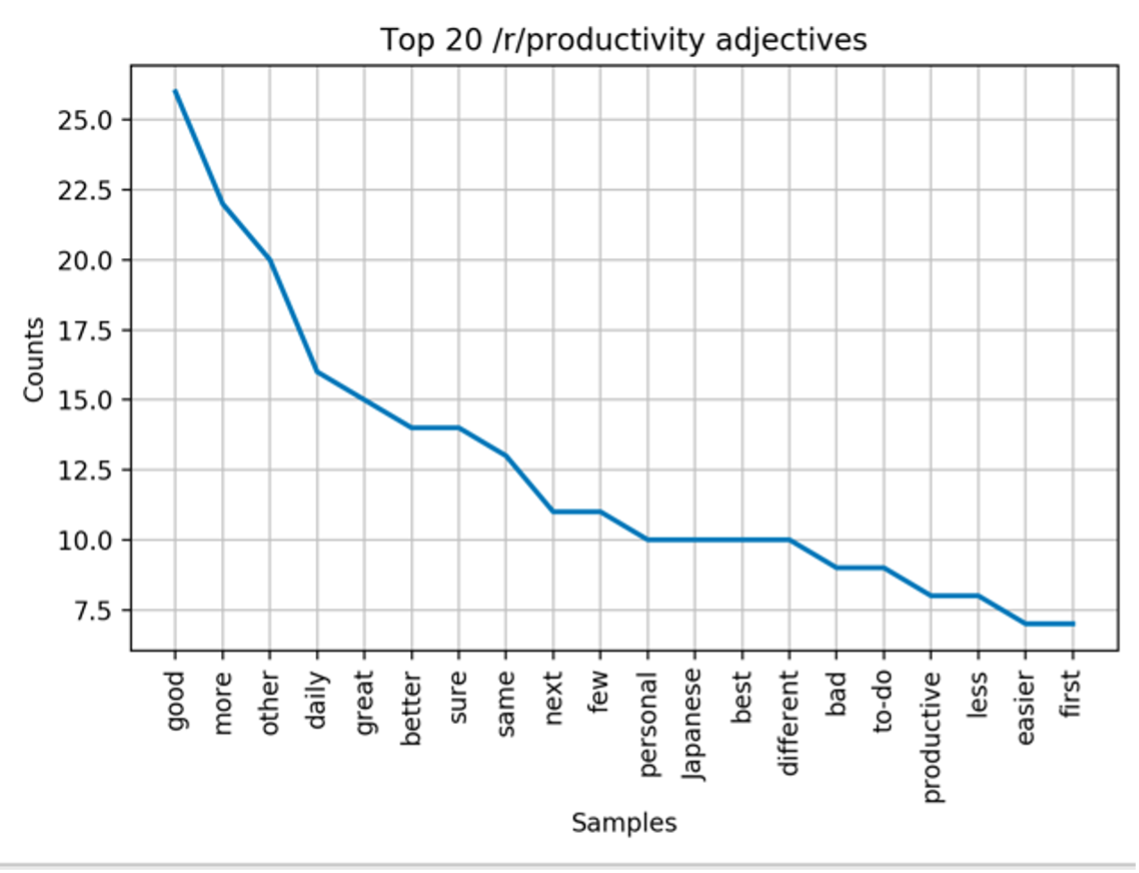
In both subreddits, the top three adjectives are ‘good’, ‘more’ and ‘other’ (with the order of ‘good’ and ‘more’ swapped in r/antiwork). These are highly frequent words in English that can occur in many contexts. This is a problem if we want to discern the connotation associated with the use of these adjectives. For example, you can use the word “good” to denote a positive emotion, such as “this spaghetti is so good” or “you’re a good egg”. However, you can use the word “good” in sentence constructions with neutral or even negative sentiment, such as “it’s a good indication that things will remain uncertain for a while” or “you’re a good liar, aren’t you?”. This issue arises when using single-word data (as opposed to multiple words or sentences). Overall, it’s hard to discern the connotation associated with adjectives without the surrounding context.
Another issue in this frequency analysis is that the sample size of words is smaller for both subreddits – there simply aren’t as many counts per word as what we can see in noun data. For example, the top adjective ‘more’ in r/antiwork has only 19 counts, whereas the top nouns in both subreddits have over 50 counts.
So, I would think of this adjective data as a fun starting point to think about the sentiment in these subreddits, rather than a reliable indication of it.
Data collection – a caveat
This part of my project was a peep into how words are used in the two subreddits using a little bit of scraped comment data. However, there are flaws with what I’ve done here.
One major flaw is that the praw function I used to scrape the comment bodies simply dives into the subreddit and scrapes any comment body until that comment count reaches 300. Depending on how many submissions were made that day, and how long each thread was, the sampled comment data can end up representing only two or three subreddit threads. I think this is why some of the data I plotted was weirdly specific (e.g., the word ‘Japanese’ appearing in the top 20 adjectives in r/productivity).
Also, when I ran the script on different days (or even hours), the top 20 words changed each time. Perhaps if I changed the script to only include the top 20 nouns or adjectives from “top comments” rather than any comments (and from “top submissions” rather than any submissions), I could get more generalised data that reflected which words are most favoured in usage in these communities.
Summary
Overall, I had lots of fun finding the top 20 nouns and adjectives for the two subreddits. It was super cool to practise using some powerful Python libraries (praw, nltk, pandas) and to think about the fascinating reasons behind word choice in two very different Reddit communities.
In terms of limitations, I had to keep in mind that my sample size was small and that my script skews my data collection to specific subreddits. I also couldn’t get much out of the adjective data without seeing the surrounding contexts of those adjectives.
This isn’t the only thing I’m doing with Reddit data by the way – I’m doing ongoing research into Reddit language data (including other subreddits) and I’m excited to keep learning and building!
2724 Words
2022-01-07 00:00