22 minutes
Reddit and language data part 2 - Generating text
1. Introduction
In this post, I’ll show you how I wrote a Python script to generate text using the bigram language model.
For my second project on this site, I wanted to learn to go beyond simply analysing language data on Reddit – I wanted to learn how to generate it.
I thought that a good first foray into language generation would be to take user comment data from a Reddit community (‘subreddit’), create a language model from the linguistic patterns of that data, and then generate new text from those patterns.
Ideally, I would be able to generate a “comment” from that model – say, twenty to fifty words long - that would mimic a ‘typical’ contribution to that subreddit. I chose two subreddits that seem completely opposed to each other in their users’ belief systems: r/skeptic and r/psychic. I took these two communities as sources of data because I was curious to see how the ethos and communication patterns in these two internet hubs might come out differently as the output of the language model.
So, I established a goal: to write a program to generate strings that mimic the language of commenters on r/skeptic and r/psychic.
2. The subreddits: skeptics and psychics
Let’s look at the characteristics of the r/skeptic and r/psychic subreddits.
The r/skeptic community is built upon the shared goal of ‘generating discussion in the spirit of scientific skepticism.’ The definition they give for this term is ‘the practice of questioning whether claims are supported by empirical research and have reproducibility’. At the time of writing, r/skeptic had just over 163,000 Reddit users subscribed to the forum.
A quick eyeball at the posts of r/skeptic reveals posts that often refer directly to media publications outside of Reddit, such as an anti-vaccine article published on an ‘alternative news’ site. The comment replies to the post are often critical, analytical, and full of quotes or paraphrases from figures of authority, just as you’d expect from a ‘sceptical’ community.
The second subreddit of my project, r/psychic, had a member count of just over 226,000 at the time of writing. It is dedicated to those interested in the belief of ‘extrasensory perception’.
The submissions in r/psychic are full of passionate, emotional descriptions of encounters with spirit guides, ghosts, and angels. Overall, the subreddit emphasises self-expression, speculation and validation of the subjective experience in the users’ contributions to the community.
Laying the subreddits side-by-side creates the source of a fascinating range of data across the emotional spectrum. One side of it is careful and analytical, and the other side is excitatory and emotive.
So, I thought it would be fascinating to use language data from these two communities. In this way, I could experiment with the output and create two types of generation based on data from contrasting sources.
3. Generating a sentence: probability and word context
How do you get a computer to generate words?
To get a computer to pick words, you must at least give it a group of possible words to pick from.
Let’s imagine a scenario where a person is sitting with a deck of 200 cards in front of them. On each card, there is a word printed on one side. Some words, such as “can”, “we”, “talk”, appear on more cards than other words do.
The person picks out one card at a time and lays out each card out on a line from left to right. The player picks out fifty cards one by one, and at the end, she has a line of cards that spell out words – a fifty-word ‘string’. Some words appear much more often than other words do. For example, the word “the” appears fifteen times in the fifty-word string, the pronoun “you” appears seven times, “think” appears five times, and “would” appears twice. The fifty-word string she picks out (i.e., “generates”) ends up being nonsensical:

The 200-card deck (i.e., the ‘language model’) had the cards for the player to pick from, but it didn’t have any context for which cards make more sense when they appear alongside each other when the player puts them down. So, the player must be able to predict which card is most likely to come next, given the cards that have just been put down.
The problem above reflects the fact that in human languages, not all words are equally likely to appear next to one another. You have certain words that are more likely to appear close to one another than others. Take for example the following sentence:
Could you please turn the light …
Which word would you choose after the word ‘light’?
The most likely contenders would be the prepositions ‘on’ or ‘off’, both of which are plausible options. What about less likely contenders? A native speaker of standard English would be unlikely to insert the words ‘under’, ‘beneath’, or ‘horse’ as the next word in this sentence.
So, a basic language model that predicts the next word in a sentence must go beyond the simple act of randomly picking words from a pre-defined list. It must be able to assign the probability of a word appearing as the next possible word given how a sentence has been constructed thus far.
4. Bigrams: calculating the probability of a sentence
To generate a sentence, you need to be able to predict the next word based on the probability that a particular word would occur. There are a few ways of going about this. However, a simple model to start with is the bigram language model.
The bigram language model calculates probabilities of each word occurring in a sentence, based on the probability of that particular word occurring after the previous word in the sentence. It segregates sentences into pairs of words that occur next to each other, and makes calculations based on these pairing patterns.
Let’s take the full sentence example: “Could you please turn the light off”. If that partial sentence were divided up into adjacent word pairs, it would be divided into six sections, like below:
1) (“Could”, “you”)
2) (“you”, “please”)
3) (“please”, “turn”)
4) (“turn”, “the”)
5) (“the”, “light”)
6) (“light”, “off”)
Each of these sections could be assigned probabilities. That is, each word pair (bigram) could be given a probability of occurring based on how often that word pairing occurs in a language, out of all the word pairings that ever occur in a language. In the table below, I assigned some made-up probabilities to each bigram from “Could you please turn the light off” to demonstrate how bigrams could get assigned probabilities based on how frequently they occur in a language.
Bigram (Made-up) probability
(“could”, “you”) 0.05
(“you”, “please”) 0.00002
(“please”,”turn”) 0.000012
(“turn”, “the”) 0.003
(“the”, “light”) 0.005
(“light”, “off”) 0.0003
In my made-up examples, I assigned “could you” as having a higher probability than “please turn”, which would mean that “could you” occurs more in speech than “please turn”. As a result, it would be more likely to be picked out as a candidate for language generation model. So, we keep a count of how often bigrams occur in language data to indicate which words are more likely to occur together.
How would we know how often a particular word pairing occurs in a language? Well, we can’t know all the possible word pairings that ever occur among speakers of a language at any given time. However, we can approximate the frequency of bigrams in a language if we work with a good language corpus. A language corpus is a collection of language data for a given language, often organised around a particular domain. For example, an Australian English language corpus could contain transcripts of all television media produced between 1970 and 1990. A linguistic researcher could have a conversational corpus of Navajo language child speakers socialising with other kids. A corpus often has a sizeable number of words that give a representative view of a particular language or dialect, within a particular domain, at a particular time.
By extracting natural language data from a language corpus, you can start creating plausible probabilities of bigrams occurring within a certain language, in a certain domain.
The table below shows how bigrams and word frequencies relate. The frequencies of specific words occurring adjacent to other words are set out along the x- and y-axis.
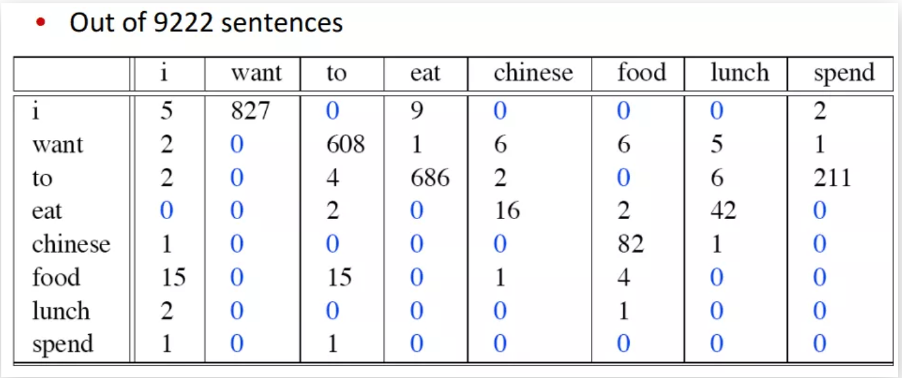
You can see that in the bigram data, certain words occur much more frequently than others. Out of the sample of 9222 sentences taken from a British telephone conversation data corpus, “I” is paired with “want” 827 times, “to” and “eat” 686 times, “to” and “spend” 211 times, and “Chinese food” 82 times. Using this data, you can assign probabilities based on the number of times those bigrams appear out of all the possible bigrams in the language corpus data. In the example above, quite a few bigrams never occur. For instance, “eat I” doesn’t occur in the sample at all, and neither does “spend want”, “lunch Chinese”, nor “eat want”. These bigrams are assigned probabilities of 0, in the crude way we’re defining here. In the real world, they would not be assigned probabilities of 0 – check out Laplace smoothing if you’re curious as to why.
These bigram probabilities can be used in language generation to pick out what the next word would likely be in a sentence, given the last word that has been generated in the sequence so far.
“I”
“I want”
“I want to”
“I want to eat”
“I want to eat Chinese”
“I want to eat Chinese food”
Let’s have a look at how you could implement the bigram model using Python and the Natural Language Toolkit (NLTK) package.
5. Putting it all together: generating strings with Python and NLTK
5.1. Scraping the comments
The first step in creating the comment generator was to create two “corpora” – one language corpus for r/skeptic, and another for r/psychic. These would act as data batches from which the frequencies of bigrams would be derived. From those frequencies, the bigram language model can be built to assign probabilities to words occurring next to one another in pairs. For this step, I would have to connect to the two subreddits directly and scrape comment data from the users contributing to these forums.
I used the praw API to connect to the two subreddits. For this step, I had to register an application on Reddit. Once this was set up, I used the following code to authorise my Python script to programmatically access the Reddit site. Note that the client_id, client_secret, and user_agent parameters would be different for someone else connecting to Reddit, so I’ve just placed “XXXXXX” in the values for these parameters.
import praw
from praw.models import MoreComments
# connect to reddit
reddit = praw.Reddit(client_id='XXXXXX’,
client_secret='XXXXXXX’,
user_agent=’XXXXXX’)
Next, I created separate ‘psychic’ and ‘skeptic’ subreddit data objects. These objects would contain corpus data from the two subreddits.
psychic = reddit.subreddit('psychic')
skeptic = reddit.subreddit('skeptic')
Then, I wrote a function scrape_comments that would trawl through the comments of the newest 200 submissions of the two subreddits (that is, newest at the time the script is run). Then, the function would store these comments to two text files for each subreddit, acting as data batches for the two subreddits.
def scrape_comments(sub):
for submission in sub.new(limit=200):
for comment in submission.comments:
if isinstance(comment.body, MoreComments):
continue
with open(f"{sub}_data_store.txt", 'a') as fh:
fh.write(comment.body + ' ')
I applied the function to the r/psychic and r/skeptic data objects so that I would have two data batches to pull from.
scrape_comments(psychic)
scrape_comments(skeptic)
I ran the scripts many times to build up each corpus text file to contain 20,000 words from r/skeptic and r/psychic, respectively.

Above is a screenshot of the first several lines of the r/skeptic corpus text file.
5.2 Gathering frequency values
Now that I had substantial data batches (“corpora”) for the two subreddits, it was time to organise the language data into bigrams and frequency distributions. This would enable the bigram language model to calculate the probabilities of different bigrams appearing in the comment data. For this task, I used the nltk modules ngrams, word_tokenize, sent_tokenize and FreqDist. I also imported the scrape_data function from my earlier comment-scraping script.
import random
from nltk import ngrams
from nltk import word_tokenize
from nltk import sent_tokenize
from nltk import FreqDist
from scrape_data import reddit
from scrape_data import psychic
from scrape_data import skeptic
Next, I wrote a function collect_data that would take the data from the batch files and created test data objects, test_data_psychic and test_data_skeptic, to pull data from the text files of the two corpora.
def collect_data(sub):
data_collection = []
with open(f"{sub}_data_store.txt", 'r') as fh:
read_file = fh.readlines()
for i in read_file:
data_collection.append(i)
return data_collection
test_data_psychic = collect_data(psychic)
test_data_skeptic = collect_data(skeptic)
At this point, we have lots of comment strings as data in our r/skeptic and r/psychic stores. However, we cannot linguistically analyse these strings without applying the tokenization method to them. Tokenizing our comment data will allow our script to process the data as separate words and sentences, rather than a random array of characters. It’s an essential step to working with bigrams, as the program would be able to recognize words within a string, and therefore process them as separate entities next to one another.
In my script, I applied a word tokenization function from nltk (word_tokenize) as well as their sentence tokenisation function (sent_tokenize) to both the r/skeptic and r/psychic data. I applied both forms of tokenization so that the script would be able to recognize separate words as well as the start and end of each sentence in the comment data.
skeptic_tokens = [word_tokenize(w) for w in sent_tokenize(str(test_data_skeptic))]
psychic_tokens = [word_tokenize(w) for w in sent_tokenize(str(test_data_psychic))]
Now, it was time to create the bigrams!
I defined a function get_bigrams that would create a list of bigrams with padding symbols to indicate the start ("<s>") and the end ("</s>") of a sentence. I wanted to make these symbols overt in the data, so that it was easy to pick out the most common first and last words of sentences in the language data. This way, the model would be better at guessing realistic first and last words while generating a sentence.
def get_bigrams(token_data):
bigrams = [list(ngrams(i, 2, pad_left=True, pad_right=True,
left_pad_symbol='<s>', right_pad_symbol='</s>')) for i in token_data]
output = [j for i in bigrams for j in i]
return output
bigrams_psychic = get_bigrams(psychic_tokens)
bigrams_skeptic = get_bigrams(skeptic_tokens)
Next, I created a frequency distribution of bigrams occurring in the r/skeptic and r/psychic corpus data. In this way, I could build up the probabilities of co-occurring words in the language data.
freq_psychic = FreqDist(filter_bigrams(bigrams_psychic))
freq_skeptic = FreqDist(filter_bigrams(bigrams_skeptic))
Lastly, I wanted a separate list of any words that occur as the first word of a sentence in the data. If a word occurred immediately after the start padding symbol, then the word’s bigram was added to this list.
# filter out start tokens in frequency data
def start_tokens_lst(frequency_data):
return [i for i in frequency_data if i[0] == '<s>']
# create starting token list for r/psychic
starting_tokens_psychic = start_tokens_lst(freq_psychic)
# create starting token list for r/skeptic
starting_tokens_skeptic = start_tokens_lst(freq_skeptic)
So, I had the frequencies of each bigram in the language data for both subreddits as well as a separate list of ‘start’ words in the data that occur as the first word of any sentences. These start words were extracted from bigrams with the first item of the bigram being the start word token. The second item of this bigram would be a word that occurs at the start of at least one sentence in the corpus data.
[('<s>', 'If'), ('<s>', 'Brilliant'), ('<s>', 'This'), ('<s>', 'They'), ('<s>', 'I'), ('<s>', 'From'), ('<s>', 'Hypotheses'), ('<s>', 'Nice'), ('<s>', 'Simple'), ('<s>', 'As')]
With this kind of information, I could get started on creating the function that actually generates sentences from an empty string.
5.3. Generating the comments
I wrote a function generate_start_token that uses the in-built Python function random.choice(). This function randomly picks out a word from the list of ‘start’ words that occur in the language corpus. The word randomly picked would be (suitably) the first word in my generated sentence.
# return random starting token from starting token list (as first word)
def generate_start_token(starting_tokens):
return random.choice(starting_tokens)
Then, I defined a list of frequency values (values_lst), which is a list of the actual numbers of times that each bigram appears in the corpus, not the bigrams themselves.
# list of frequency values from freq bi list
# values_lst = [i for i in freq_bi.values()]
Now, it was time to create the main function, which generates a string of twenty words.
def generate_string_by_freq(freq_bi, starting_tokens):
start = generate_start_token(starting_tokens)
string = start
last_word = start
counter = 20
while counter > 0:
items_lst = [freq_bi[i] for i in freq_bi if i[0] == last_word[1]]
max_value = max(items_lst)
lst = [i for i in freq_bi if i[0] == last_word[1]]
if counter % 2 == 0:
append_item = random.choice([i for i in freq_bi if i[0] == last_word[1] and freq_bi[i] == max_value])
else:
append_item = random.choice([i for i in freq_bi if i[0] == last_word[1]])
string = string + append_item
if append_item[1] == '</s>':
update = random.choice(starting_tokens)
else:
last_word = append_item
counter = counter - 1
output = list(string)
return " ".join(output[1:][::2])
Let’s break this one down.
start = generate_start_token(starting_tokens)
string = start
last_word = start
First, I had a start word randomly picked using the generate_start_token function. This would give us our first word in the sentence. Then, I created a variable string that assigned that first word as its value. I also created that first word as the value of a variable last_word. The ‘last_word’ variable is the last word that has been assigned to the string within the function loop. This will keep being updated as more words get added to the string.
Next, I assigned a counter to the function that dictates how many words the script would add to the string. I set the initial counter value at twenty, so that the number of words in my string would be twenty.
counter = 20
Then, I created a while loop that would use this counter function to generate the twenty words in the sentence. A condition was placed on the way the words would be picked out from the corpus data.
while counter > 0:
items_lst = [freq_bi[i] for i in freq_bi if i[0] == last_word[1]]
max_value = max(items_lst)
if counter % 2 == 0:
append_item = random.choice([i for i in freq_bi if i[0] == last_word[1] and freq_bi[i] == max_value])
else:
append_item = random.choice([i for i in freq_bi if i[0] == last_word[1]])
If the counter was sitting on an odd number, then the next word would be chosen from the corpus data if, in the data, it occurs immediately after the word that has just been added to the string. If the counter was sitting on an even number, then the next word would be chosen from the corpus data if it occurs immediately after the last word added to the string AND it is the word that occurs most frequently in that particular position, that is, immediately after the previous word.
I chose this method because I wanted the generated comments to reflect highly frequent words in the data, as well as less frequent words occurring in the data. In real life, speakers of a language don’t always choose the most frequent words, especially if it’s in a context of social expression or critique – instead, they are likely to choose a combination of highly frequent words and less frequent words. So, my counter loop would have half the words chosen based on the maximum probability of that word’s position, and the other half chosen randomly.
Each time this loop would run, I would append the bigram of the newly generated word to the ‘string’ tuple (string = string + append_item), which would help build up the sentence string. Then, I set a conditional for the ‘last_word’ variable. If the last generated word occurs before an end token symbol, indicating that it occurs as the last word of a sentence, then I would generate a new start word as the last_word. Doing so would start a new sentence for the next part of the comment string. If the most recently generated word does not occur before an end token, then the ‘last_word’ would be updated to be its bigram. In this way, I could make a comment string that has several sentences.
string = string + append_item
if append_item[1] == '</s>':
last_word = random.choice(starting_tokens)
else:
last_word = append_item
No matter what the outcome of the loop was, each time it was called, it would decrement the counter by one. When the counter reached zero then the looping would terminate.
counter = counter – 1
The final lines of the program put the chosen bigrams into a list and returned the output of the function in a readable string format.
output = list(string)
return " ".join(output[::2])
Let’s have a look at some of the results in the next section.
6. Results
To communicate the results of the bigram model, let me first show you what the generation looked like with a unigram model.
In a unigram model, each word in a sentence is assumed to occur independently of any other words surrounding it. So, the probability of a word’s occurrence is not calculated based on any words that have preceded it. As we know now, in a bigram model, the calculation of a word probability considers the context of the word immediately preceding it.
I tested out what the results would look like with just a unigram model. Here is a sample of that from the r/skeptic data:
All guy used enough prized got the fall test wrong way we I the 1,700 are to to be some what have the way our health evidence do despair possible 18 is who 'm up broken years ' get part dealing this people spend readers some -- to mention and respond problem going would say he blocked horrible way crunchy understand So right are had when bias that too approach I ve thinking ’ arent by young the brain people demonstrable they valves narratives bring under they a in experience wonder though
The text in the output of the unigram model is very strange. It shows some common words that do occur in the subreddit data, but that is where it stops. The words do not coalesce smoothly. There are word repetitions that would never occur in natural speech, like “to to”. As a result, the unigram language model shows little semblance to what a comment would look like in the reddit subcommunities.
Afterwards, I tested out the results with the bigram model and after implementing the generation function ‘generate_string_by_freq’ outlined in section 5. The results of that are listed in the table below, containing five examples from the two subreddits. The data from the two r/psychic and r/skeptic corpora were put through the same function, but they generated different ‘moods’ based on the language that real commenters use in the communities.
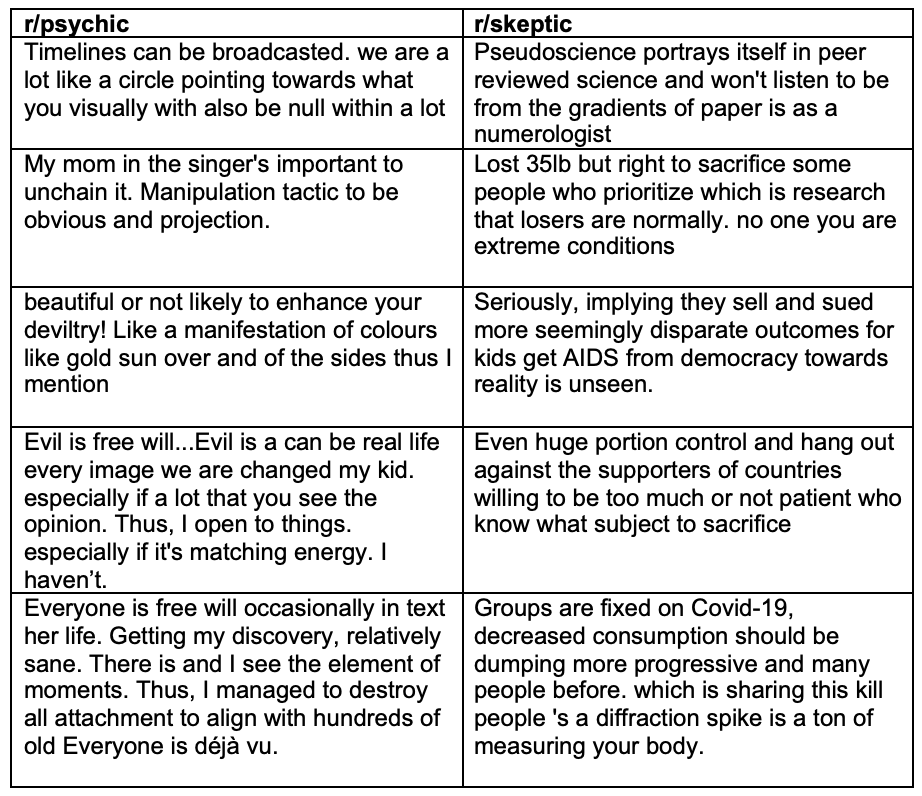
The bigram output is easier to read than the unigram output because word context is now accounted for. However, there are some other elements at play that are preventing the generated comments from looking realistic.
The main limitation is in the way the generated comments flow on the sentence level. If you segmented the comments into sections of two words each, each section would make sense. Take for example the generated sentence “Vote for the Church covered, and Harris where nutters are eating like I’d be removed Stores that classic CJD”. If you split this sentence up into sections of word pairs, each word pair looks realistic: “Vote for”, “the Church”, “are eating”, “I’d be”, et cetera. However, when you string the entire sentence together, it does not flow smoothly at all, and it makes little sense.
The bigram data has helped with some of the comments’ realism, in that the grammaticality between words is kept intact in a way that the unigram model output does not demonstrate. For example, the instances of strings like “we are a lot like a circle pointing”, “the supporters of countries willing to be too much”, and “that losers are normally” all adhere to English-like patterns, such as subject-verb agreement (“losers are”, “we are”) and the use of nouns after prepositions (“of countries”). However, the lack of comprehensibility on the level of the entire sentence shows the limitations of implementing just a basic bigram model for language generation. Without the extra methods that would unify the words beyond their relation to the immediately preceding word, it does not look like a ‘true’ comment in the holistic sense.
That being said, the comments show some mimicry of user comments in the two subreddits. It gives some clues as the overall sentiment of contributions to the communities. Let’s pick out a specific contrasting pair:

Many of the r/psychic comment strings focus on subjective experience, a pattern indicated by frequently generated 1st person pronouns (‘I’, ‘we’, ‘my’) alongside nouns that focus on personal experience and emotion (‘discovery’, ‘attachment’). On the other hand, the comment strings generated with the r/skeptic data employ more 3rd person pronouns and referents (‘they’, ‘kids’), indicating that the users are often talking about groups outside of themselves as subject matter. I also noticed that the r/skeptic comments made many more references to specific world events, such as COVID-19, the AIDS crisis, US elections, or anti-vaxxer protests. In contrast, the r/psychic comments made less reference to particular global incidents or points of history. Instead, the subject matter was often of a more generalised spiritual nature, such as the concepts of ‘déjà vu’, ‘manifestation’, or ‘free will’. These differences in subject matter reflect the dissimilarities of the two subreddits – one is focused on personal and generalised human experiences, whereas the other aims to break down specific global events while striving for a ‘third-person’ lens.
7. Conclusion
I would describe my first experiences in language generation to be somewhat successful. However, there are certainly a lot of limitations to the method I used. I would say that the text that my script generated did reflect the general mood of comments from both communities. But, while the comments made sense on the two-word level, it often wasn’t fully comprehensible on the sentence level. So, there was still a lot of room for improvement to make the comments more realistic looking.
Overall, I found this project to be a great learning experience in encountering the challenges of language generation. I would be fascinated to learn how to make generated text comprehensible on the sentence level. It would also be cool to find out about other methods to generate the probabilities of words (or sentences) occurring within a language.
For my next project on this site, I think I’ll take a break from the Reddit data stuff and focus on a different interest. I have a friend who wants to do some of her own research into the ways people use a particular type of sentence in English. I offered to help her out on that by getting useful data from massive English corpora. So, stay tuned, I could be inspired by that!
4525 Words
2022-10-03 00:00